
2025 年 3 月 21 日,腾讯正式推出自研深度思考模型混元 T1 正式版,并同步在腾讯云官网上线。这款基于混元 Turbo S 架构的强推理模型,通过工业界首创的 Hybrid-Mamba-Transformer 融合模式,在保持业界领先性能的同时,将推理成本大幅降低至竞品四分之一,引发行业高度关注。
创新架构突破性能瓶颈
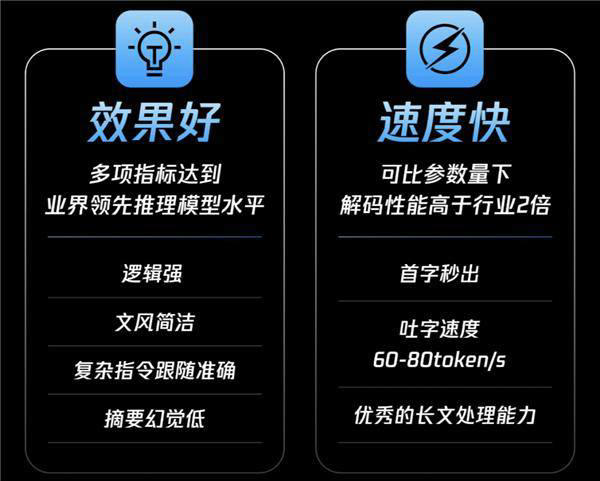
混元 T1 正式版采用的混合 Mamba 架构,首次实现了超大型推理模型的无损应用。该架构通过动态调整注意力机制,将传统 Transformer 结构的计算复杂度降低 30%,同时减少 KV-Cache 内存占用 40%,使模型在同等算力条件下的解码速度提升 2 倍。实测数据显示,混元 T1 吐字速度可达 60-80tokens/s,首字响应时间突破 1 秒,显著优于行业主流模型。
在长文本处理方面,混元 T1 通过长文捕捉技术和专项优化,有效解决了上下文丢失和长距离依赖难题。其支持的超长上下文窗口和阶梯式训练策略,使其在 4000 字以上的复杂文本处理中表现突出,摘要准确率较传统模型提升 25%。
成本优势重塑市场格局
混元 T1 的定价策略成为其核心竞争力。当前腾讯云 API 定价为输入 1 元 / 百万 tokens,输出 4 元 / 百万 tokens,与 DeepSeek-R1 标准时段的输出价格(16 元 / 百万 tokens)相比,成本仅为 25%。即使与优惠时段的竞品价格(4 元 / 百万 tokens)相比,混元 T1 仍保持相同性价比。这一价格体系为开发者提供了更具吸引力的选择,尤其在大规模商业应用场景中优势明显。
技术验证显示,混元 T1 在 MMLU-PRO、CEval 等权威基准测试中表现优异。其 87.2 分的 MMLU-PRO 成绩仅次于 OpenAI 的 o1 模型,在逻辑推理任务中得分 93.1,超越 DeepSeek-R1 等竞品。在复杂指令跟随、数学推理等场景中,混元 T1 通过强化学习和课程训练,实现了与人类专家的高度对齐。
生态布局加速技术落地
混元 T1 已深度融入腾讯产品矩阵,腾讯元宝、腾讯文档、微信读书等十余款应用已接入该模型。在工业界,腾讯通过开源中小规模模型和提供 API 服务,推动 AI 技术普惠。据财报显示,腾讯 2024 年 AI 研发投入达 707 亿元,2025 年将持续加码算力基础设施建设,计划新增 390 亿元资本开支用于 AI 领域。
面对行业竞争,腾讯混元团队表示,未来将聚焦模型轻量化和多模态能力扩展。通过与 DeepSeek-R1 等模型的差异化定位,混元 T1 将在长文本处理、低延迟响应等场景中构建独特优势。随着国产大模型开源进程加速,混元 T1 的技术架构和成本控制模式,或将为行业提供重要参考。
© 版权声明
本站内容文章版权归作者所有,未经允许请勿转载,如转载必须注明出处。
THE END










暂无评论内容